本帖最后由 taizer 于 2013-12-15 14:35 编辑
电源和机箱将是本系列文章的完结篇章,在正式开始说东西前,请允许我自顾自的说些题外话。 我写这个东西的初衷是想依靠里面所讲的东西,让看完它的人可以举一反三,初步具备自我判断硬件规格的能力,而不被媒体的炒概念性的东西给牵着走。 当然,等我写完才发现这个目标似乎很难实现了。我原本打算由浅至深的来逐渐说明,可真正当我开始写的时候才发现很不现实,硬件知识浩如烟海,提起笔来就感到了莫名的恐惧, 我一度对这篇文章的是否能真正完成产生过怀疑。 我的一位硬件好友对这篇文章缺乏基础性的知识提出了抗议,在这里不得不说明一下。 这四篇东西的文本总量在如此压缩的前提下依旧达到了接近七万字,要知道这不是写小说类别的东西,这是纯粹的计算机技术类文档, 有时候我为了说明哪怕一个很小的细节都要花上很多的时间去找图,配上说明。也许只是短短几句话依旧会消耗大量的时间。 如果加上基础性的内容,那么文本容量就会达到一个我个人无法承受的程度,毕竟我只能依靠业余休息的时间来写。 加之考虑到基础性的内容在网络上还是比较容易找到的,多方权衡后,我决定只讨论较为重要的信息。 你们所看到的从第一篇到完结篇耗时不到一年,实际上这是有草稿的情况下。 我原本预计的完成时间大概在2010年底左右,而我有写这个东西的想法则要早的多。 论坛上大量重复的信息和帖子漫天盖地,因此我就产生了写一个覆盖较广的东西的想法。 写这个东西实际上也是个自我学习的过程。很多东西我也记不太清楚,等到要成文的时候就需要精确的数字和分析了, 我不得不去重新查,在查阅的过程中又牵涉到了其他的东西,于是又决定新添加些什么。 就是这样在大结构不变的前提下,缓慢的增加了不同的内容和分析。 我的床头在写硬件百科全书期间一直放着一支笔一个小本子,就是怕睡前或者刚起来的时候突然想到了什么过后会忘记,要赶紧记下来。 由于我觉得坐床上用笔记本写东西会觉得别扭,不得不用台式机写,这些天还算不错,写板卡章的时候,正是天冷的时候,很受罪。 3DM的前身是叫3DHM,主要的事业是illusion公司的游戏汉化,现在一部分3DM玩家就是在那个时期因为这样的事情被吸引而来。 我来3DM的原因更加非主流,现在3DM比较火爆的囧来囧去,其前身应该是“爆笑网文”,更新又很快,我那时候基本天天来看。 那时候年幼无知笑点很低,经常一个人坐在那笑的接不上气。当然后来我果然发现了3DM的大杀器:illusion社的汉化游戏,我也就毫无疑问的定居了。 直到今天,我也对鸟姐参与汉化illusion游戏的行为本身感到空前的正能量。一个女人,义无反顾的投身到面向扣脚大叔的成年人指向游戏的汉化工作中去,这是怎样的一种精神! 后来3DM成为了国内汉化的标杆,在作为一个伸手党的同时也有了做点贡献的想法。加之3DM的硬件区算是很干净的了,于是这里成为了硬件百科全书的首发及仅发论坛。 由于各种我们已知各种的原因,在我们这个国度里,信息和全球的同步率不是很高。 唯独硬件这个区域,中国玩家获取信息的速度和全面性丝毫不亚于发达国家,甚至中国硬件玩家的整体水平我认为还高过发达国家。 从某个层面上说,硬件这个领域是值得我们这些玩家去珍惜的,难得真●全球领先水平啊。 硬件带给我的东西有很多很多,很大一部分甚至还有精神层面的东西。 我这人爱好广泛了点,漫画美剧历史军事经济,还听摇滚看看圣经爱达经什么的,乱七八糟什么都来点,但真正让我消耗了大量的时间精力的估计只有硬件吧。 有时候一种爱好带给你的不仅有精神上的充实,还有一个完整的世界。每个人都想活的和别人不一样,就像中二病里说的那样,“人这一辈子都是中二病患者”。 DIY在现在这个时代正在走向廉价化和简单化,有时候我会突然怀念那个电脑城卖家都需要知道如何用DOS来分配内存的时代, 那个主板没有固态电容和封闭电感却布满元器件的时代,那个一个不讲究卖相的时代,那个没有那么多夸张的概念炒作的时代。 硬件论坛总有一个很奇怪的现象,就是吵,吵架的吵。很多帖子往往没有任何实际性的内容,起一个很有争议性的标题,于是一帮子人在里面吵的都快骂了娘。 图什么许的这是?! 论坛的本职任务是讨论不是争论,这有本质上的区别。我知道A知识但不完整,你知道B知识也不完整,讨论过后,我们拥有完整的AB知识体系。 争论呢?惹一肚子气,而且最终的结果,我相信我的A系统是完整和正确的,你坚持的你的B体系是完整和正确的,于是我们两个带着不完整甚至是不正确的认知参与到下一场战斗中去了。 硬件玩家另一个奇怪的现象就是对立性。有品牌偏向很正常,但你不应该把其他品牌偏向的玩家放到你的对立面。 你总不能因为自己喜欢波大的,就把觉得平胸才是宝库的人放到自己的对立面去吧。大家都是喜欢胸的,大小什么的搁一边,我们都是好战友好同志,是吧? 一个硬件产品永恒无法完美,它本身就包含了价格性能功耗做工品牌附加等多种属性, 因此一旦把对硬件的问题稍微拔高一点,就会立刻形成相对宏观的问题,而问题一但宏观就很难分出对错。 所以,当你陷入到这样一种论战的时候,甭回复了,没结果的。“唾面自干”与君共勉。
写道这里我突然想起一件在显卡篇忘记提的事情,就是入门级显卡的大容量显存问题。 通常的观点是,入门级显卡的性能如此低下,配备超大容量显存根本没有任何作用,就是为了欺骗没有硬件知识的购买者而作出的设定。 其实这仅仅是一个方面。Ram是要成本的,入门级显卡何苦要增加自己的成本呢?更多的考虑可能是为了对未来游戏的兼容性。 实际上大多数玩家都不是画质党,很多人对游戏显卡的需求也仅仅停留在可以体验游戏的层面,一块显卡能让他在低画质下体验游戏就足够了。 由于游戏本身纹理库的大小,游戏本身会综合考量场景的纹理缓冲而对游戏显卡有个最低的容量要求。 入门级显卡正是为了其将来依旧能满足新游戏的显存容量要求而做出这种显存设定的。 比如过去性能相当不错的7600GT 128m /128bit在一些游戏里就无法运行,即使他的性能可以运行。
继续扯淡。你们有没有见过硬件玩家相处无比和谐的地方呢?好好想一想,有的!
答案是成年人论坛。 我相信大家都同意这样一个前提,硬件论坛和成年人论坛的用户有大范围的交集,简单的说,很多人是一波人。 你见过喜欢欧美的和喜欢日本的吵架么,你见过喜欢漫画的和喜欢真人的吵架么,你见过喜欢无码的和喜欢有码的吵架么,你见过喜欢高树玛丽亚的和喜欢苍井空的吵架么。 为什么,在那个环境里大家都友好互助,彼此理解,互相尊重。而一回到自己个儿的地盘就不行了呢? 我建议当你拾掇好片儿刀、板砖、鸡蛋准备出去干人的时候,先问自己一句:这人有可能是我在××论坛的前辈,帮过我很多(种子),我是不是真的要去干他? 在这里,我对本文还有最后一个愿景。 我希望有人能对本系列文章进行补充和修改,最终完善它,使之真正成为献给硬件玩家的一道盛宴而不是咸菜。我也会尽快放出文档版下载。 本次,不再有开头小段,也许大家会失望了。不过,在本文完结之后,我稍作休息,会专门来写无节操小段,到时候就发到囧来囧区吧。 本章节共分为两个大的部分:电源以及机箱。电源将涉及如下几个方面 1.基本的元器件2.拓扑结构3.输出质量的分析;机箱则分为1.扩展性2.散热和兼容性3.细节设计。 当然最终成文可能略有不同或者完全不是我开头说的这回事也是极有可能的。习惯就好了。 我会先给出大概的图表,方便描述元器件的时候能更加直观。 只介绍一些当前常见的拓扑方案,对于早期落后方案或者小众方案不再赘述,电源的输出质量会结合元器件进行部分介绍,各个部分并没有明显的界限,互相渗透。 最初我希望能以一个具体的电源作为模板来说明,后来发现如果这样做反倒不够全面,最终的描述方恐怕会有点乱,尽力为之吧。 部分图来自CHH,G大的电源测试,有些方案G大的图基本算是独一家,调戏G大的1个小时也解决了不少我的疑惑,深表感谢。特地说一下。 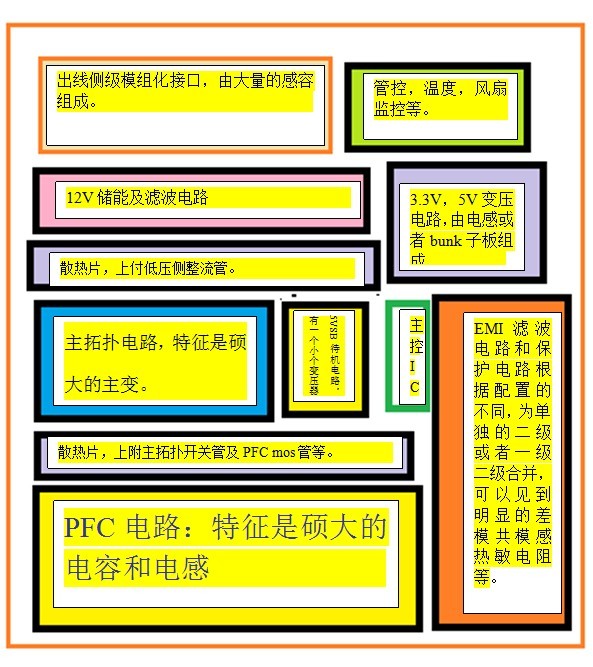
1.正激 半桥之后最常用的一种拓扑。特点是成本适中,高速开关保证了电压稳定性较好,由于输入和输出的同时进行,转换效率也有一定的保证。 如果用料有一定程度的保证,则能在电源输出的绝大多数参数中都有上佳表现。分为单管和双管两种。 有源箝位技术,常常作为一种补充出现在正激电源中。 有源箝位从本质上来说仍旧属于软开关管技术,使得开关管的导通电压进一步降低,从而形成几乎零损耗,通过对电感储能的回收利用进一步提升电源的转换效率。 有源箝位的正激电源可以看到谐振电容(不太好找),以及额外的箝位开关管,以上是辨别方法。 在500W-800W级别电源中,个人最倾向于正激+有源箝位+DC-DC的方案,可以在输出质量、转换效率、成本上取得极好的平衡。
2.LLC谐振 LLC谐振是目前最普遍的高转换效率电源拓扑方案,基于软开关管技术,可以在较低的成本下实现较高的转换效率。 缺点在于,谐振在进行电压反馈调校的时候会有额外的相位叠加,也就是说电压稳定性要次于正激拓扑,环路响应也是缺陷。 不过目前依靠优秀的二次侧调校和高端PWM-IC,高端LLC已经进入了一个相对高输出质量的时代。现在就着LLC我要说说80plus认证的问题。
首先,我要说明80plus认证的高低和一款电源的质量并没有紧密联系。 一个电源除了输出的功之外,剩下无奈消耗掉的就是元器件的发热,也就是不做功能耗。 如果我们简单的去理解下,在拓扑不变的前提下,要提高一个电源的不做功功耗,就是要降低元器件的发热功耗,通常的解决办法是将被动元器件换为主动元器件。 这一手段会增加成本,提升效率,加上主动元器件的开关速度更高,一般来说也会改善输出质量。 知道什么的转换效率能接近100%么?
答案是一根导线 将电源的问题的无限扩大化就是,如果设计无视输出质量,就可以采用各种方法去减少元器件的发热,最简单的也是最恶心的就是减少元器件。 加上LLC这种天生低成本软开关技术的存在,更是给低端金牌电源铺了一条相当坑人的道路。 电源不像其他配件,有的可以用跑分软件,有的可以用超频软件,都很容易衡量其好坏,电源一直缺乏一个有说服力的行业标准, 80plus认证神奇的成为一个标准过后,并且被媒体不停吹捧,现在某种意义上设置成为厂家和玩家的双重负担。 厂家可能为了挤进某个效率线而不得不放弃一些更好的设计,或者增加不必要的成本,而玩家则要去负担80plus这一认证费用,虽然认证前后电源不会变好或变坏。 80plus的初期认证是有能源补贴的,现在虽然已经没有了,但它已经成为一个行业标准了,厂家只能顺从这一现状。80plus的认证费用以出货量来计算,而且费用不菲,完全是额外的成本。
80plus的真正好处在于,一个高转换效率电源证明其在发热上非常的低,元器件负担较小,预期的稳定性较为客观。 其二,一个经过80puls认证的电源,一旦我们看到了其拆解知道了其内部方案,那么根据它的型号购买,日后买到的会和我们看到的一样。 也就是说80puls的零售版不能够随意改动元器件,如果刀了你会知道(改动主要元器件要按要求送测新方案,并在原型号上加上后缀编号,加以区分)。 当然不排除无良商家私自改动,但这毕竟是极少数。
谐振拓扑不需要储能电感,也加重了LLC先天的波纹缺陷,滤波电路一般配置较为豪华,算上谐振电容的存在是判断其拓扑的主要方法。 谐振电容有时候会隐藏在谐振电感下,有时候谐振电感会和主变合并,有时候还会添加一个互感器用于IC监控电流,因此元器件布局整体上会有些变动。 待机变压器上一般能看到导线引出,上图的谐振电感应该就是合并了。由于全桥LLC不是交错开关,它的驱动变压器也是只有一个,只能从开关管的数量上判断(全桥一般是4个)。
1:待机变压器2.主变3.谐振电感4.谐振电容5.互感器6.全桥驱动变压器注意互感器是接到PWM IC的,方便IC直接监控电流,这互感器可以省略。
3.ZVS移相全桥 主要应用于高端大功率电源,其拓扑特性使得其可以在大功率级别上做到输出质量的高水准,当面对1500W+这种级别,双双管正激或者全桥LLC都显得力不从心。 ZVS移相全桥是一种高成本的软开关管解决方案,其整流桥和PWM电路成本都相对更高,特殊的移相交错上下臂交替占载特性使得输出相位产生抵消. 加上可以使用倍整流技术,具备天生的高效、稳压、低波纹、快速响应等特性。 如果使用其他拓扑来实现类似的输出方式,比如LLC交错,整体成本可能会更高,而且相比ZVS仍旧在响应上会有差距。 双驱动器,谐振感,和双12储能是ZVS的显著特征,只有少数ZVS拓扑不利用倍整流特性而配置单储能。 倍整流的双电感处于交错模式,轮流储能和滤波,波纹互相消退,因此相对来说ZVS的12V滤波电路可以简单一点。
| 


 [复制链接]
[复制链接]







 发表于 2013-5-16 01:43
发表于 2013-5-16 01:43





 收藏
收藏